
Cross Modal Focal Loss for RGBD Face Anti-Spoofing
This is a summary and review of the recent paper on face anti-spoofing by George and Marcel 2021, presented at CVPR 2021.
The main contribution of the paper is to propose a method for combining RGB and depth information. Some possible strategies are
- Early fusion. RGD and depth images are stacked to form a 4-channel input to a CNN. See e.g. MC-PixBiS by Heusch et al. 2020..
- Late fusion. Each channel is passed through its own CNN and the embeddings are concatenated before the Softmax layer. See e.g., MCCNN by George et al. 2019.
- Score-level fusion. Each channel is passed through its own CNN to obtain a score. Aggregation is performed on the scores, using simple averaging, a logistic regression or some other ML model.
- Multi-level fusion. Each channel is passed through a CNN with connections between the CNNs at intermediate layers. See e.g., Parkin and Grinchuk, 2019.
This paper proposes a mix between late fusion and score-level fusion.
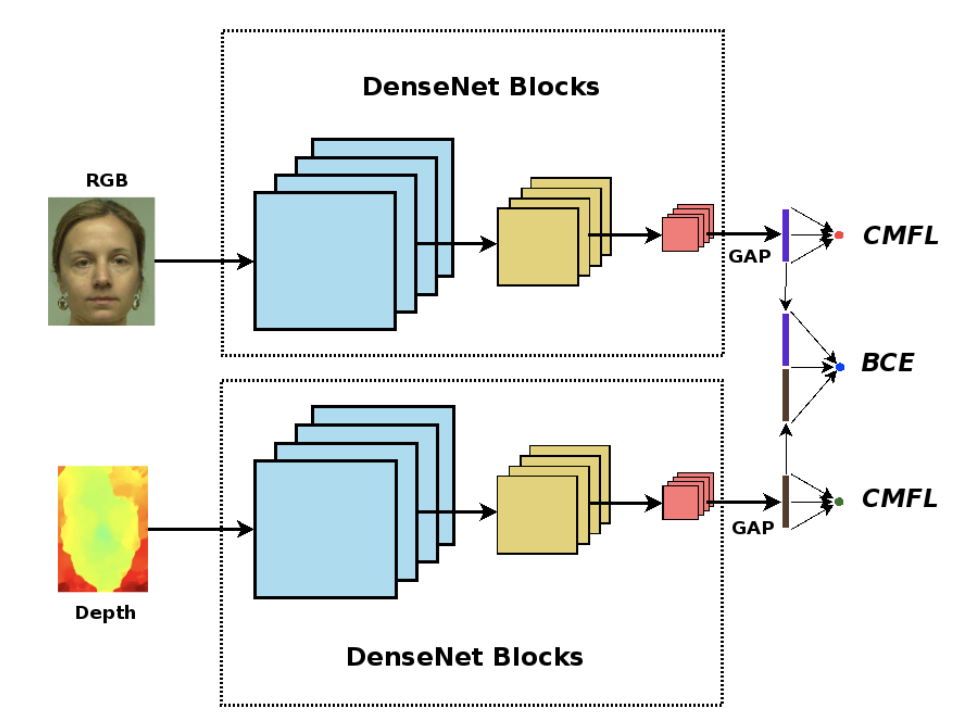
Architecture of the cross modal focal loss paper (Source: George and Marcel, 2021)
Each channel is passed through its own DenseNet network, and the output is fed into three losses.
- A binary cross-entropy loss on the concatenated features in the spirit of late fusion.
- A loss on the ouput of each separate channel leading to a score for each channel in the spirit of score fusion. The novelty is loss function used for these outputs.
To fix notation, let \(y \in \{0, 1\}\) be the label, where \(y=0\) is a spoof and \(y=1\) is a genuine. Let \(p\), \(q\) be the probabilities output by the RBG and depth streams respectively. The usual cross-entropy loss for RGB is
\[\begin{aligned} \mathcal L_{CE}(p, y) &= -y \log p - (1-y) \log (1-p) \\ &= - \log p_t\,, \end{aligned}\]where \(p_t\) is the probability of the target class, i.e.,
\[p_t = \begin{cases} p\,, & y = 1 \\ 1-p\,, & y = 0 \end{cases}\,.\]In this paper the authors propose the following Cross Modal Focal Loss (CMFL), here for the RGB stream,
\[\mathcal L_{\mathrm{CMFL}}(p, q, y) = -\alpha (1 - w(p_t, q_t))^\gamma \log p_t\,,\]where \(w(p, q) = q \frac{2pq}{p + q}\) is the probability of the other channel multiplied by the harmonic mean of the two probabilities. Essentially, if the depth channel is very certain about its classification, then we discount the loss contribution from the RGB channel and vice versa.
The method is evaluated on the WMCA and HQ-WMCA datasets using the leave-one-out protocol: one attack is removed from the train and test datasets and the model is evaluated on genuine samples and spoofs with this one attack type. The purpose of this protocol is to test the generalization ability to unseen attack types, although it is debatable how realistic this protocol is in commercial settings.
The results are mixed: For within-dataset evaluation the method shown improvement over baseline methods when averaged across attack types, but is not consistently better for each attack type. The baseline methods perform better in cross-dataset evaluation.
The authors are planning to release the source code in the future.