
Face Recognition Research at FG 2020
This post reviews papers from the IEEE FG 2020 conference that deal with face recognition.
How are attributes expressed in face DCNNs?
by Prithviraj Dhar, Ankan Bansal, Carlos D. Castillo, Joshua Gleason, P. Jonathon Phillips, and Rama Chellappa.
In this paper the authors look at how much information about face attributes is encoded in face embeddings by networks trained for face recognition. This question is interesting for two reasons: First, some attributes such as wearing eyeglasses or having a moustache are not defining a person’s identity and ideally embeddings used for face recognition tasks should not encode this information; Second, attributes such as gender or race are coupled with identity, however, reliance on these attributes for face recognition could be a source of bias.
The topic is receiving considerable attention lately with different papers looking at it from different sides. For example, how does one measure the amount of information about a face attribute contained in a face embedding? One can train an NN classifier to predict the attribute from the embedding, use partial least squares (see next review), or follow the authors of this paper and use mutual information.
The authors estimate the mutual information between face attributes (gender, yaw and age) and features at various layers of the network. They track how mutual information evolves through the layers of the network as well as over the course of training. The problem with mutual information is that computing it is a non-trivial task, especially for high-dimensional data. One has to choose an approximation method and in this paper the authors use MINE, which uses a NN to estimate a lower bound for mutual information. Alluding to the fact that they are working with an estimate of mutual information, they use the term expressivity in place of mutual information.
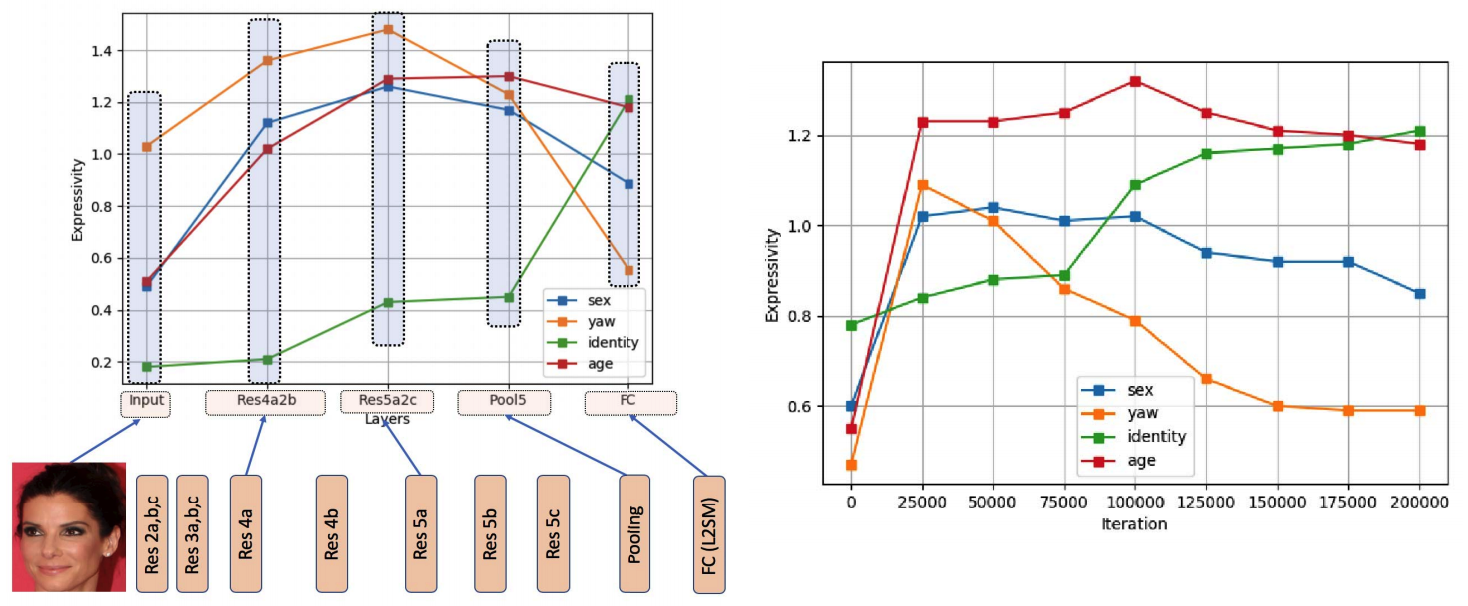
Figures 3 and 4 from the paper.
A sample of results for a ResNet-101 trained on MS-Celeb-1M and applied to IJB-C is shown in the above figure. Sex, yaw and age are encoded as continuous random variables. To encode sex the authors use the probability of being male as output by a gender prediction method. Identity is encoded using discrete numerical identity labels. On the whole, expressivity for identity increases with the depth of the layer as well as with training, while expressivity for sex, yaw and age decreases. This seems in line with expectations. The network is paying more attention to identity and less attention to confounding factors although whether or not sex is a confounding factor is debatable.
The question remains, what exactly is expressivity measuring? Expressivity is defined as an approximation to mutual information. The data processing inequality (DPI) would require that the mutual information between features and any attribute decreases as we go deeper into the network. As the authors note, this is not the case. The authors remark, that this is because “the features in our context denote representation, rather than information content described in Information Theory.” To be honest, I don’t quite know what this means. Violation of the DPI certainly implies that expressivity is not measuring the same as mutual information, but no explanation is given, what it is measuring instead. A recent review of information plane analyses for neural networks argues that estimates of mutual information measure geometric effects, such as clustering or shrinking in latent space rather than information theoretic ones. This hypothesis could also be applicable to this work.
Face Attributes as Cues for Deep Face Recognition Understanding
by Matheus A. Diniz and William R. Schwartz.
This is another paper that looks at how information about face attributes is processed and encoded by networks trained for face recognition. This paper in particular looks not just at the face embeddings, i.e., the output of a face recognition model, but also t each intermediate layer, allowing them to see how information flows through the network.
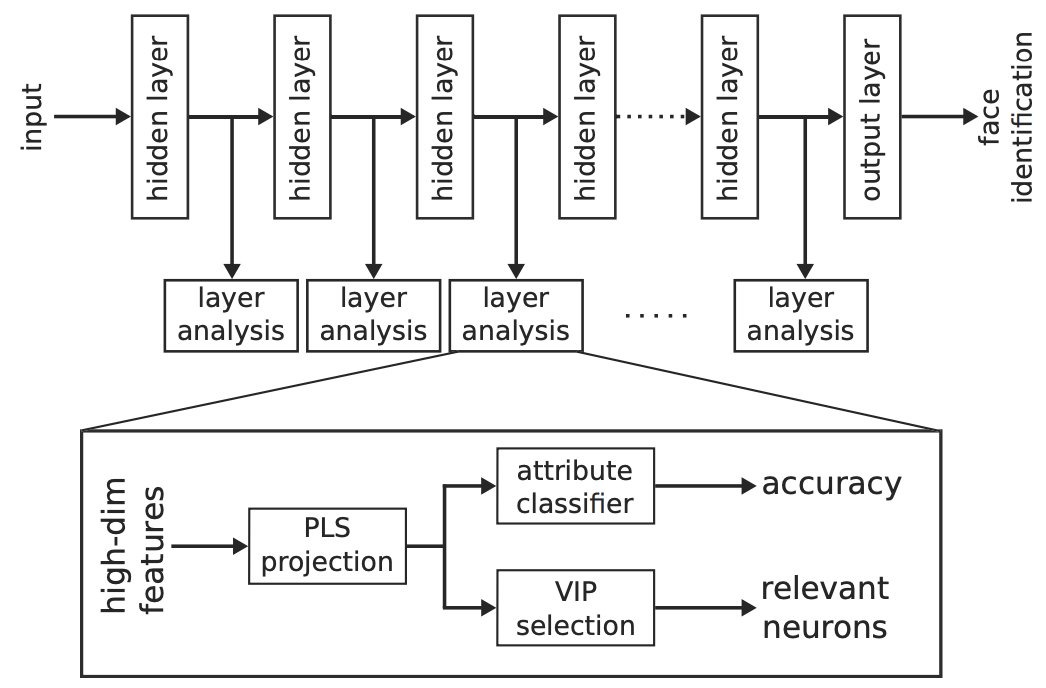
Figure 2 from the paper showing their approach to attribute prediction.
The authors use a ResNet-50 trained on VGGFace2 and the 40 binary attributes from CelebA. Unfortunately they do not provide any information about the face recognition accuracy of the trained model. For each intermediate layer and each target attribute they use partial least squares (PLS) to reduce the feature dimension to 8 and then train a quadratic classifier to predict the attribute. They also calculate the importance of each neuron using VIP scores and try to predict the attributes using only the most important neurons or channels, which gives an indication how localised the attribute information is in the network.

Figure 2 from the paper. Blue: prediction using PLS-reduced features; Green: prediction using top-8 channels; Orange: prediction using top-8 neurons.
One can make a couple of interesting observations:
- Some attribute prediction such as grey hair are very accurate, while predictions for seemingly similar attributes such as brown hair are much less accurate.
- On the whole accuracy curves plateau quite quickly or exhibit only a modest slope indicating that shallow features are discriminative enough for the attribute prediction task.
- Orange curves, obtained using only 8 neurons to predict an attribute, reach the level of blue curves, usually towards the deeper layers. This indicates that in deeper layers attribute information is quite localised, while shallow neurons lack the receptive fields to predict the attributes.
- The saw-tooth pattern arises due to skip connections in residual blocks. The local maxima correspond to layers after the skip connection has been added.
The paper provides an interesting addition to the list of works investigating the relationship between face recognition and face attribute prediction, and adds to the evidence that these two tasks are more entangled than we would like.
Learning Privacy-Enhancing Face Representations Through Feature Disentanglement
by Blaž Bortolato, Marija Ivanovska, Peter Rot, Janez Križaj, Philipp Terhörst, Naser Damer, Peter Peer, and Vitomir Štruc.
This is another paper that tries to remove gender information from face embeddings learned for a face recognition task. While other papers attempted this in order to create a less gender-biased model, here the motivation is to remove information in order to increase privacy.
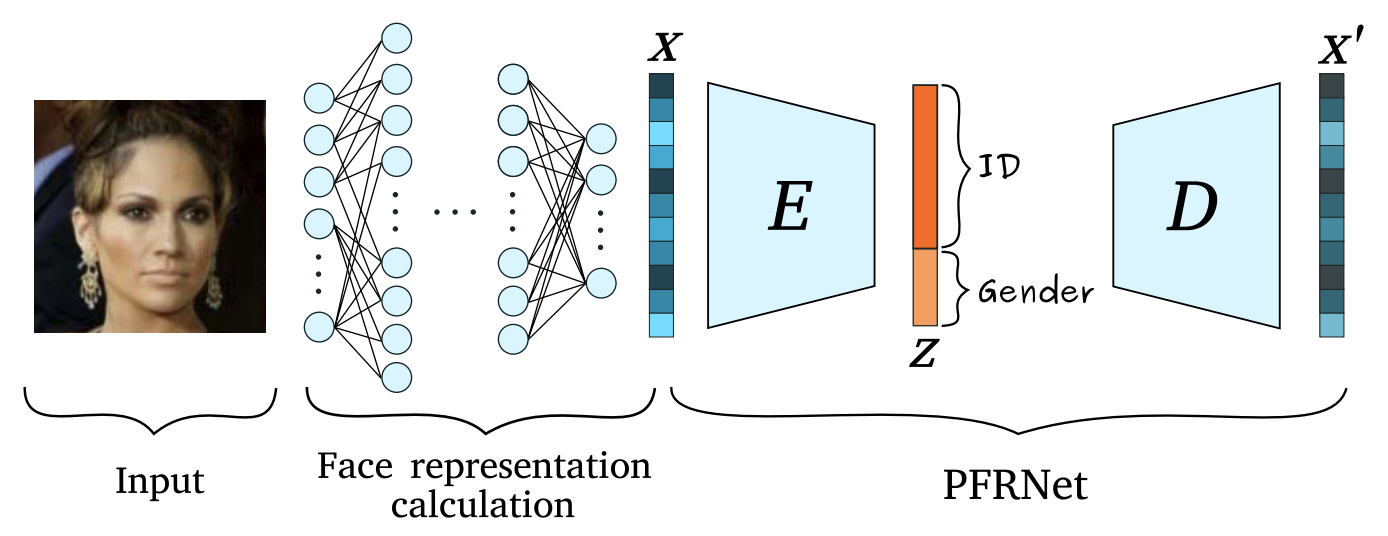
Figure 1 from the paper.
The authors use a ResNet-50 trained on VGGFace2 from this repository. Their method consists of training an auto-encoder \(D \circ E(x)\) on the face embeddings $x$ generated by ResNet-50, such that the latent representation \(z=E(x)\) can be split, \(z=(z_{\text{ind}}, z_{\text{dep}})\), into a part \(z_{\text{ind}}\) that encodes only identity information and a part \(z_{dep}\) that encodes gender information. The idea is to use only \(z_{\text{ind}}\) to perform face recognition.
They use a sum of three losses to train the auto-encoder. The first is a simple reconstruction loss, \(\mathcal L_0 = \| x - D \circ E(x) \|_{L^2}\). The second loss align the distributions of \(z_{\text{ind}}\) for male and female subject, thus suppressing gender information in \(z_{\text{ind}}\). This happens by comparing the \(\alpha\)-order moments (\(\alpha=0, 1, 2\)), estimated using mini-batches, of each component of \(z_{\text{ind}}\) via
\[\mathcal L_{\alpha} =\| \langle z^\alpha_{\text{ind}} \rangle_{f} - \langle z^\alpha_{\text{ind}} \rangle_m \|_{L^2}\,.\]The third loss aims to separate the distributions of \(z_{\text{dep}}\) by gender using the \(\beta\)-order moments (\(\beta=0, 1, 2)\) of the distributions of \(z_{\text{dep}}\).
\[\mathcal L_{\beta} =\exp \left( -\| \langle z^\beta_{\text{dep}} \rangle_{f} - \langle z^\beta_{\text{dep}} \rangle_m \|^2_{L^2}\right)\,.\]The total loss is a weighted sum of these three losses.
Any method that removes information from face embeddings has to satisfy two properties: it has to successfully remove sensitive information, but at the same time it must maintain the face recognition accuracy. The main issue with the paper is that it is impossible to evaluate the second property. The authors do not evaluate the face recognition accuracy of their model on any of the standard benchmarks. They evaluate on LFW in terms of the equal error rate (EER), which is not the standard metric reported for LFW. And for their method EER on LFW increases from 1.8% to 2.8% after removal of gender information which is an increase of more than 50%. Considering that LFW is an easy benchmark for face recognition, this does not bode well for proposed method…
Robustness Analysis of Face Obscuration
by Hanxiang Hao, David Güera, Janos Horváth, Amy R. Reibman, and Edward J. Delp.
This paper analyses how effective various face obscuration methods are at guaranteeing the privacy of the faces being obscured. They look at three types of methods: traditional methods such as Gaussian blurring, k-same based obscuration methods that aim to obscure the identity while preserving non-identifiable information such as gender or pose, and encryption-type methods such as P3.

Figure 1 from the paper.
The authors look at face verification attacks, where they fine-tune a face recognition network on both clear and obscured images as well as face reconstruction attacks using Pix2Pix (it is unclear whether the network was fine-tuned for the particular task).
The main conclusion from the paper is that neither traditional nor encryption-type (P3 and scrambling) face obscuration methods are able to guarantee privacy against an attacker who has knowledge of the obscuration method and the ability to apply deep learning, although these methods successfully defeat human vision. This implies that we cannot rely on human judgement alone when selecting a face obscuration method in sensitive applications.
IF-GAN: Generative Adversarial Network for Identity Preserving Facial Image Inpainting and Frontalization
by Kunjian Li and Qijun Zhao.
In this paper the authors propose a GAN-based method, named IF-GAN, that performs both face inpainting and frontalisation. The architecture of the method is shown below.

Figure 2 from the paper.
The input is an image together with a binary mask, that defines the occluded regions. The inpainting model uses a U-Net architecture with partial convolutions, which are able to deal with arbitrary occlusion shapes. The frontalisation model has two pathways: a local pathway operating on patches around the eyes, nose and mouth and a global pathway that operates on the whole image; the two pathways are merged at the bottleneck layer of the U-Net architecture.
The model is trained with three types of losses: three adversarial losses (inpainting, local and global) to ensure the generated image looks real; three pixel-wise losses (inpainting, local and global) that compare the generated image against ground truth; and an identity-preserving loss that uses a pre-trained CosFace to compare face embeddings extracted from the frontalised image against those extracted from the ground truth frontal image.
The model is trained on the Multi-PIE and Multi-dim datasets. Training itself proceeds in three stages: first the frontalisation module is trained on unoccluded images; then the inpainting module is trained while the frontalisation module is frozen. Finally, the whole network is trained end-to-end.

Figure 4 from the paper.
Qualitatively, the results looks very good. The authors also evaluate how effective IF-GAN at improving face recognition performance. However, to do that they use a model trained only on LFW and evaluated on Multi-PIE. Given the current state-of-the-art in face recognition, it is difficult to draw any conclusions from a face recognition model trained only on LFW.
While the method does show promising qualitative results, the authors do mention two drawbacks of their method: First, at inference time we require not only the partially occluded image, but also an occlusion mask. Second, training requires paired frontal and profile images captured under controlled conditions, which are difficult to acquire in large amounts. The authors intend to overcome both issues in future work.