
Fair Loss: Margin-Aware Reinforcement Learning for Deep Face Recognition
This post is a review of the paper “Fair Loss: Margin-Aware Reinforcement Learning for Deep Face Recognition” which was presented at ICCV 2019.
Current state-of-the-art methods for training face recognition models, such as ArcFace or CosFace, use an additive margin in the loss function to improve the separation between classes. These methods use a fixed margin for all classes and by doing so they ignore the fact that training sets can be unbalanced: there are some some classes (identities) with many samples followed by a long tail of classes with few samples each.
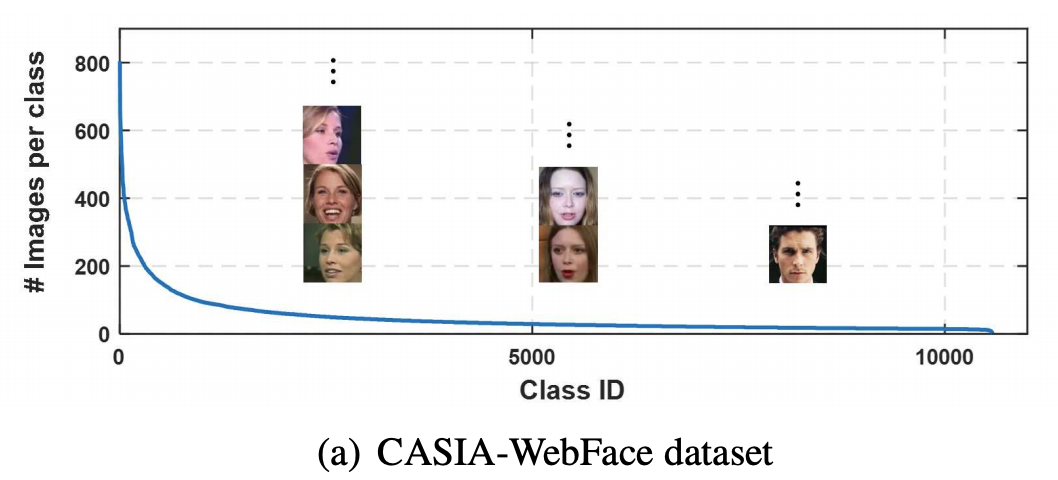
The question this paper sets out to answer is: Can we do better? Can we learn a margin that is adapted to features of the class and by doing so improve the training process? The answer seems to be: Yes, we can, but computationally it does not come cheap.
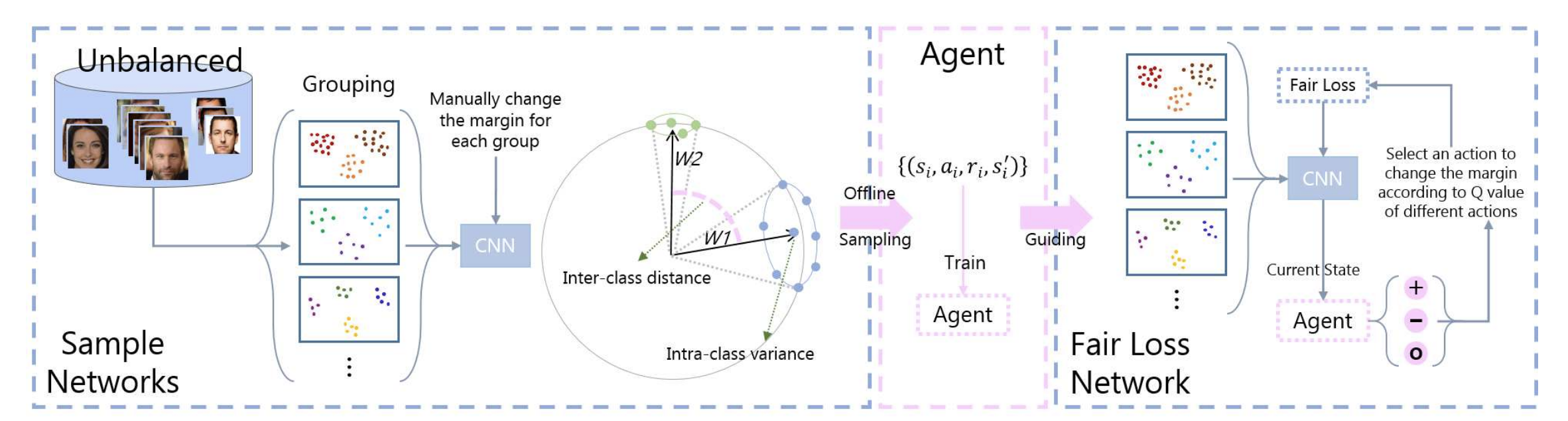
In a nutshell, we want to use deep-Q learning to learn a policy that can be used to progressively adapting the margin for each class during the training process. For this to be feasible, we will not choose a different margin for each class, but rather bin classes into larger groups based on three characteristics:
- Number of samples per class (3 groups)
- Intra-class variance of face embeddings (3 groups)
- Current margin (0.15, 0.25, 0.35 or 0.45)
This gives us a state space with 36 elements. We also have 3 actions: increase the margin, decrease the margin or keep it the same.
The computationally expensive part is to collect training samples to train the policy network. To calculate the reward (changes in inter- and intra-class distances between embeddings) associated to a state (a group with a margin) and an action (how to change the margin for the group) we need to fine-tune a pre-trained face recognition model with the loss function defined by the new margin for a certain number of iterations. Then we can extract the embeddings with the fine-tuned network and are able to calculate the reward. Once the training data has been collected, the policy network itself is easily trained.
With the trained policy network we can then proceed to train the CNN we are actually interested in using. The Fair Loss training procedure is to change the margin for each group after each epoch with the new margin given by the policy network.
Now the important question: How well does it work? As every self-respecting research paper they show improvement over the chosen baselines. The results on the MegaFace benchmarks are roughly comparable to those obtained by CosFace. Better than the single model CosFace results, but slightly worse than the 3-patch ensembles.
The real question however is: How long did it take to collect the training samples to train the policy network? The paper is surprisingly silent on the topic. And are there more efficient ways to spend this computational budget?